
Introduction
In real-world fintech systems, small bugs can turn into high-impact production incidents especially when blockchain transactions are involved.
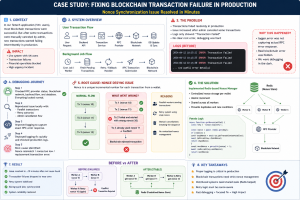
This case study explains how we debugged and fixed a critical blockchain transaction failure issue in a live production system serving around 1 million users, caused by a nonce synchronization problem in RPC-based blockchain transactions.
The issue was not obvious at first, logs were misleading, and only after deep debugging we identified the root cause and fixed it quickly using a Redis-based nonce management system.
System Overview
Before jumping into the issue, here is the system architecture we were working with:
Components:
- Backend: Node.js (Backend services)
- Blockchain Layer: Ethereum-compatible chain
- RPC Provider: Third-party blockchain RPC service
- Background Workers: Cron jobs + queue workers
- Retry System: Custom retry + fallback transaction handler
- Cache Layer: Redis (for some state management)
High-Level Architecture Flow
User Request
↓
Backend API
↓
Transaction Service
↓
RPC Provider (Blockchain Network)
↓
Blockchain Confirmation
↓
DB Update + Status SyncBackground Job Flow (Important for Issue)
Cron Job / Worker
↓
Fetch Pending Transactions
↓
Retry / Fallback Handler
↓
RPC Transaction Submission
↓
Blockchain NetworkThe Problem
Issue Observed
In production:
- Most transactions were working fine
- But some transactions started failing randomly
- Issue increased after admin manually canceled some transactions
Impact:
- Live system (1M users)
- Financial transactions affected
- High urgency production incident
Initial Symptom
Logs only showed:
Transaction FailedBut there was:
- No proper error message
- No RPC error details
- No blockchain response insight
This made debugging difficult.
Phase 1: Initial Investigation
We first checked:
What we verified:
- RPC provider status → OK
- Blockchain network → Stable
- Backend API flow → Working
- Database consistency → OK
But still:
Failures were happening intermittently
Problem in Logging Layer
We discovered:
logger.error()was not capturing full RPC error response
So instead of:
nonce too low
replacement transaction underpriced
invalid nonceWe only saw:
Transaction FailedPhase 2: Reproducing the Issue
To debug properly:
Steps taken:
- Replicated production environment locally
- Simulated:
- Multiple parallel transactions
- Retry scenarios
- Admin cancellation flow
- Added enhanced logging
Key Improvement
We updated logging:
Before:
logger.error("Transaction failed")
After:
logger.error("RPC Error Response", error.response || error.message)Phase 3: Root Cause Discovery
After deploying improved logs, real error appeared:
nonce mismatch / nonce too low / replacement transaction errorRoot Cause
Blockchain Nonce Desync Issue
In blockchain systems: Nonce = unique incremental number for each transaction from a wallet
What went wrong?
Because we had:
- Parallel workers
- Retry system
- Manual admin cancellations
- Multiple background cron jobs
Nonce tracking got out of sync
Simple Explanation
Think of nonce like a queue number:
Transaction 1 → nonce 10
Transaction 2 → nonce 11
Transaction 3 → nonce 12Transaction 2 fails → retried again with wrong nonce
Transaction 3 already used same nonce
→ Conflict occurs
→ Blockchain rejects transactionProblem Summary
- No centralized nonce tracking
- Multiple workers generating transactions simultaneously
- Retry system reusing stale nonce values
- Admin cancellation disrupted nonce sequence
Flow of Failure
Worker A → nonce 10 → sent
Worker B → nonce 11 → sent
Worker A retry → nonce 10 again conflict
Blockchain → rejects transactionSolution Design
Goal:
Make nonce:
- Consistent
- Shared across workers
- Atomic (no duplication)
Final Fix: Redis-Based Nonce Manager
We introduced a central nonce manager using Redis.
Why Redis?
- Fast (in-memory)
- Atomic increment support
- Shared across multiple workers
- Prevents race conditions
New Flow
Worker requests nonce
↓
Redis checks latest nonce
↓
Returns + increments safely
↓
Transaction sent to RPC
↓
Blockchain confirmsFixed Architecture
┌──────────────┐
│ Redis │
│ (Nonce Store) │
└──────┬───────┘
↓
Worker A Worker B Worker C
↓ ↓ ↓
Get nonce from Redis (atomic)
↓
Send to RPC Provider
↓
Blockchain NetworkImplementation Concept
Pseudo Logic:
async function getNonce(wallet) {
const key = `nonce:${wallet}`;
const nonce = await redis.get(key);
if (!nonce) {
const chainNonce = await rpc.getTransactionCount(wallet);
await redis.set(key, chainNonce);
return chainNonce;
}
const nextNonce = parseInt(nonce) + 1;
await redis.set(key, nextNonce);
return nextNonce;
}Deployment & Fix
After implementing:
- Redis nonce manager
- Improved logging
- Retry sync adjustment
We deployed the fix.
Result
- Issue identified: ~10–15 minutes
- Fix deployed: same cycle
- System stabilized immediately
Outcome
- Transaction failures dropped to near zero
- Retry system became stable
- Background jobs synchronized properly
- Production restored safely
Key Learnings
1. Logging is everything
Without proper logs, root cause stays hidden.
2. Blockchain systems need strict state control
Nonce mismanagement breaks entire transaction flow.
3. Distributed workers need shared state
Local memory is not enough.
4. Retry systems can cause hidden bugs
Retries must be nonce-aware.
Final Summary
A critical production issue in a fintech blockchain system was caused by:
Nonce desynchronization due to parallel workers + retries + cancellations
We fixed it by:
Implementing Redis-based centralized nonce management
Improving logging for RPC error visibility
Synchronizing transaction flow across workers
Result:Issue resolved in minutes, system fully stabilized